Note
This page renders committed notebook outputs. The Read the Docs build does not execute notebook code.
Robustness sweeps as diagnostic evidence#
Current surface: V0.29.
Purpose#
Treat perturbation sweeps as diagnostics, not guarantees: inspect residual RMS, conditioning, span distance, and verification error together.
What you will learn#
How noise, subsampling, and fit epsilon change generator evidence.
How to read singular values and condition numbers as fit-health diagnostics.
How Heat and Burgers use the same confidence-card language without implying universal robustness.
Required extras#
Matplotlib for compact diagnostic plots; included in .[test].
Expected runtime#
About 1-2 minutes.
Out of scope#
No robustness theorem, no benchmark success claim, no automatic threshold policy, no new fitting algorithm.
These notebooks are tutorials, not API contracts. Example outputs are runtime summaries, not canonical paper artifacts.
[1]:
from pathlib import Path
import sys
ROOT = Path.cwd()
if not (ROOT / "pyproject.toml").exists():
ROOT = ROOT.parent
if str(ROOT) not in sys.path:
sys.path.insert(0, str(ROOT))
import numpy as np
import matplotlib.pyplot as plt
from notebooks._tutorial_utils import confidence_card, print_cards
from pdelie.data import add_gaussian_noise, generate_burgers_1d_field_batch, generate_heat_1d_field_batch, subsample_time, subsample_x
from pdelie.derivatives import compute_spectral_fd_derivatives
from pdelie.reporting import summarize_generator_fit_diagnostics, summarize_residual_batch, summarize_verification_report
from pdelie.residuals import BurgersResidualEvaluator, HeatResidualEvaluator
from pdelie.symmetry import fit_translation_generator
from pdelie.verification import verify_translation_generator
CONFIG = {
"fit_epsilons": [1e-5, 1e-4, 1e-3],
"noise_fraction": 0.02,
"span_tolerance": 5e-2,
}
CONFIG
[1]:
{'fit_epsilons': [1e-05, 0.0001, 0.001],
'noise_fraction': 0.02,
'span_tolerance': 0.05}
1. Build matched train/heldout variants#
Each row below fits on one variant and verifies on the matching heldout variant. This keeps the comparison focused on perturbation sensitivity rather than shape mismatch.
[2]:
base_train = generate_heat_1d_field_batch(batch_size=4, num_times=33, num_points=64, seed=620)
base_heldout = generate_heat_1d_field_batch(batch_size=3, num_times=33, num_points=64, seed=621)
variants = {
"clean": (base_train, base_heldout),
"noisy_2pct": (
add_gaussian_noise(base_train, std_fraction=CONFIG["noise_fraction"], seed=622),
add_gaussian_noise(base_heldout, std_fraction=CONFIG["noise_fraction"], seed=623),
),
"time_stride_2": (subsample_time(base_train, stride=2), subsample_time(base_heldout, stride=2)),
"x_stride_2": (subsample_x(base_train, stride=2), subsample_x(base_heldout, stride=2)),
}
{key: value[0].values.shape for key, value in variants.items()}
[2]:
{'clean': (4, 33, 64, 1),
'noisy_2pct': (4, 33, 64, 1),
'time_stride_2': (4, 17, 64, 1),
'x_stride_2': (4, 33, 32, 1)}
2. Sweep fit epsilon and keep the evidence visible#
[3]:
evaluator = HeatResidualEvaluator()
records = []
for variant_name, (train, heldout) in variants.items():
residual = evaluator.evaluate(train, compute_spectral_fd_derivatives(train))
residual_summary = summarize_residual_batch(residual)
for epsilon in CONFIG["fit_epsilons"]:
generator = fit_translation_generator(train, evaluator, epsilon=epsilon)
verification = verify_translation_generator(
heldout,
generator,
evaluator,
span_tolerance=CONFIG["span_tolerance"],
)
fit_summary = summarize_generator_fit_diagnostics(generator)
verification_summary = summarize_verification_report(verification)
card = confidence_card(
label=f"{variant_name} epsilon={epsilon:g}",
residual=residual_summary,
fit=fit_summary,
verification=verification_summary,
)
card["variant"] = variant_name
card["fit_epsilon"] = epsilon
records.append(card)
print_cards(records[:6])
[
{
"condition_number": 1592402.5811672113,
"evidence_label": "direct_svd_in_tolerance",
"first_epsilon": 0.0001,
"first_error": 4.514761151902394e-09,
"fit_epsilon": 1e-05,
"fit_mode": "svd",
"label": "clean epsilon=1e-05",
"max_error": 4.49785044070442e-06,
"reference_fallback_used": false,
"residual_max_abs": 7.923377265028897e-05,
"residual_rms": 1.5219882569749286e-05,
"selected_span_distance": 1.0096847977793663e-05,
"singular_value_count": 4,
"svd_span_distance": 1.0096847977793663e-05,
"variant": "clean",
"verification_classification": "exact"
},
{
"condition_number": 1592402.2067103665,
"evidence_label": "direct_svd_in_tolerance",
"first_epsilon": 0.0001,
"first_error": 4.514761151902394e-09,
"fit_epsilon": 0.0001,
"fit_mode": "svd",
"label": "clean epsilon=0.0001",
"max_error": 4.49785044070442e-06,
"reference_fallback_used": false,
"residual_max_abs": 7.923377265028897e-05,
"residual_rms": 1.5219882569749286e-05,
"selected_span_distance": 1.0096841488075772e-05,
"singular_value_count": 4,
"svd_span_distance": 1.0096841488075772e-05,
"variant": "clean",
"verification_classification": "exact"
},
{
"condition_number": 1592402.1679358482,
"evidence_label": "direct_svd_in_tolerance",
"first_epsilon": 0.0001,
"first_error": 4.514761151902394e-09,
"fit_epsilon": 0.001,
"fit_mode": "svd",
"label": "clean epsilon=0.001",
"max_error": 4.49785044070442e-06,
"reference_fallback_used": false,
"residual_max_abs": 7.923377265028897e-05,
"residual_rms": 1.5219882569749286e-05,
"selected_span_distance": 1.009684104362181e-05,
"singular_value_count": 4,
"svd_span_distance": 1.009684104362181e-05,
"variant": "clean",
"verification_classification": "exact"
},
{
"condition_number": 21.417299025350534,
"evidence_label": "direct_svd_out_of_tolerance",
"first_epsilon": 0.0001,
"first_error": 0.00043939046954815053,
"fit_epsilon": 1e-05,
"fit_mode": "svd",
"label": "noisy_2pct epsilon=1e-05",
"max_error": 0.43939046954755706,
"reference_fallback_used": false,
"residual_max_abs": 14.710257947945559,
"residual_rms": 1.9607738077410153,
"selected_span_distance": 1.1298559903521876,
"singular_value_count": 4,
"svd_span_distance": 1.1298559903521876,
"variant": "noisy_2pct",
"verification_classification": "failed"
},
{
"condition_number": 21.41729902524864,
"evidence_label": "direct_svd_out_of_tolerance",
"first_epsilon": 0.0001,
"first_error": 0.00043939046954725487,
"fit_epsilon": 0.0001,
"fit_mode": "svd",
"label": "noisy_2pct epsilon=0.0001",
"max_error": 0.43939046954667976,
"reference_fallback_used": false,
"residual_max_abs": 14.710257947945559,
"residual_rms": 1.9607738077410153,
"selected_span_distance": 1.1298559903545764,
"singular_value_count": 4,
"svd_span_distance": 1.1298559903545764,
"variant": "noisy_2pct",
"verification_classification": "failed"
},
{
"condition_number": 21.41729902525099,
"evidence_label": "direct_svd_out_of_tolerance",
"first_epsilon": 0.0001,
"first_error": 0.0004393904695468112,
"fit_epsilon": 0.001,
"fit_mode": "svd",
"label": "noisy_2pct epsilon=0.001",
"max_error": 0.43939046954663763,
"reference_fallback_used": false,
"residual_max_abs": 14.710257947945559,
"residual_rms": 1.9607738077410153,
"selected_span_distance": 1.1298559903547096,
"singular_value_count": 4,
"svd_span_distance": 1.1298559903547096,
"variant": "noisy_2pct",
"verification_classification": "failed"
}
]
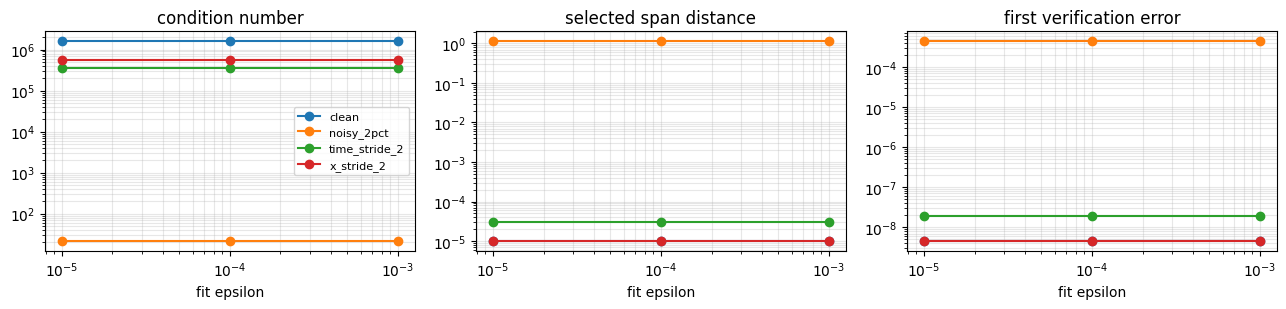
3. Plot the diagnostics rather than hiding them#
The point is not to declare one scalar winner. You want to see when conditioning, residual error, and verification disagree.
[4]:
fig, axes = plt.subplots(1, 3, figsize=(13, 3.2))
for variant_name in variants:
rows = [row for row in records if row["variant"] == variant_name]
eps = np.asarray([row["fit_epsilon"] for row in rows], dtype=float)
cond = np.asarray([row["condition_number"] for row in rows], dtype=float)
span = np.asarray([row["selected_span_distance"] for row in rows], dtype=float)
err = np.asarray([row["first_error"] for row in rows], dtype=float)
axes[0].loglog(eps, cond, marker="o", label=variant_name)
axes[1].loglog(eps, span, marker="o", label=variant_name)
axes[2].loglog(eps, err, marker="o", label=variant_name)
axes[0].set_title("condition number")
axes[1].set_title("selected span distance")
axes[2].set_title("first verification error")
for ax in axes:
ax.set_xlabel("fit epsilon")
ax.grid(True, which="both", alpha=0.3)
axes[0].legend(fontsize=8)
plt.tight_layout()
4. Same diagnostic language on Burgers#
Burgers is included to show that the confidence card is a reporting pattern, not a Heat-specific metric. The exact thresholds remain task-specific.
[5]:
burgers_train = generate_burgers_1d_field_batch(batch_size=4, num_times=33, num_points=64, seed=624)
burgers_heldout = generate_burgers_1d_field_batch(batch_size=3, num_times=33, num_points=64, seed=625)
burgers_evaluator = BurgersResidualEvaluator()
burgers_residual = burgers_evaluator.evaluate(burgers_train, compute_spectral_fd_derivatives(burgers_train))
burgers_generator = fit_translation_generator(burgers_train, burgers_evaluator, epsilon=CONFIG["fit_epsilons"][1])
burgers_verification = verify_translation_generator(burgers_heldout, burgers_generator, burgers_evaluator)
burgers_card = confidence_card(
label="burgers diagnostic check",
residual=summarize_residual_batch(burgers_residual),
fit=summarize_generator_fit_diagnostics(burgers_generator),
verification=summarize_verification_report(burgers_verification),
)
print_cards([burgers_card])
[
{
"condition_number": 1199.3791068536707,
"evidence_label": "reference_fallback",
"first_epsilon": 0.0001,
"first_error": 2.540177684328114e-09,
"fit_mode": "reference_fallback",
"label": "burgers diagnostic check",
"max_error": 2.5137922401083095e-06,
"reference_fallback_used": true,
"residual_max_abs": 9.002696193464998e-06,
"residual_rms": 9.971877293088462e-07,
"selected_span_distance": 0.0,
"singular_value_count": 4,
"svd_span_distance": 0.4443193452662649,
"verification_classification": "exact"
}
]
Recap#
A robustness sweep is useful because it exposes disagreements between residual health, fit conditioning, span recovery, and finite-transform verification.
Common pitfalls#
Reporting only the best-looking coefficient vector.
Turning one perturbation sweep into a robustness guarantee.
Comparing variants with different residual targets or incompatible shapes.
Treating condition numbers as pass/fail without context.
Extension ideas#
Add a Fisher-KPP row and compare against Heat/Burgers.
Sweep verification epsilon grids separately from fit epsilon.
Save confidence cards as your own experiment logs outside the notebook.
What to read/run next#
Run 03_portability_round_trips.ipynb to see why serialized generators should be revalidated.