Note
This page renders committed notebook outputs. The Read the Docs build does not execute notebook code.
xarray Dataset ingestion: the safe data ecosystem doorway#
Current surface: V0.29.
Purpose#
Show the narrow V0.29 xarray.Dataset path: inspect a Dataset, choose one scalar data variable, provide explicit metadata, convert to FieldBatch, and continue with readiness/residual workflows.
What you will learn#
How Dataset readiness differs from canonical
FieldBatchreadiness.Why Dataset attrs are useful clues but not canonical metadata.
How automatic data-variable selection works only when the Dataset is unambiguous.
How
from_xarray_dataset(...)delegates to the existing DataArray path after selection.
Required extras#
Install .[xarray] or .[test]; Matplotlib is used for tutorial plots.
Expected runtime#
Less than 1 minute.
Out of scope#
No file loaders, no NetCDF/Zarr readers, no broad adapter registry, no metadata inference engine, no resampling, and no multidimensional or nonuniform support.
[1]:
import sys
from copy import deepcopy
from pathlib import Path
ROOT = Path.cwd()
if not (ROOT / "pyproject.toml").exists():
ROOT = ROOT.parent
if str(ROOT) not in sys.path:
sys.path.insert(0, str(ROOT))
import numpy as np
import xarray as xr
from notebooks._tutorial_utils import (
field_snapshot,
plot_component_statuses,
plot_field_heatmap,
plot_label_strip,
pretty_json,
)
from pdelie.data import from_xarray, from_xarray_dataset, generate_heat_1d_field_batch
from pdelie.reporting import summarize_field_batch_readiness, summarize_xarray_dataset_readiness
from pdelie.residuals import HeatResidualEvaluator
CONFIG = {
"seed": 28028,
"batch_size": 2,
"num_times": 17,
"num_points": 32,
}
CONFIG
[1]:
{'seed': 28028, 'batch_size': 2, 'num_times': 17, 'num_points': 32}
1. Build a Dataset that looks like something from a lab notebook#
The Dataset has named coordinates and attrs. PDELie will report those clues, but canonical conversion still requires explicit metadata from the caller.
[2]:
source = generate_heat_1d_field_batch(**CONFIG)
metadata = deepcopy(source.metadata)
metadata["parameter_tags"] = dict(metadata["parameter_tags"])
metadata["parameter_tags"]["equation"] = "heat_1d"
dataset = xr.Dataset(
data_vars={"u": (source.dims, source.values)},
coords={name: values for name, values in source.coords.items()},
attrs={"source": "tutorial_generated_heat", "note": "attrs are hints, not canonical metadata"},
)
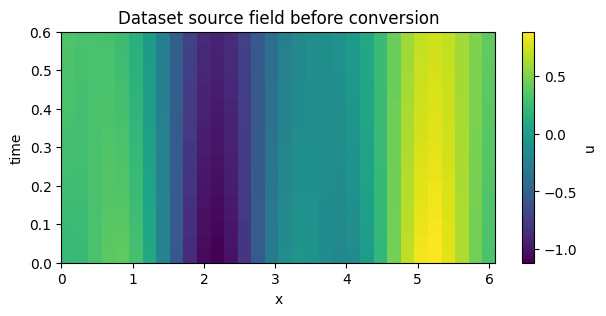
print(dataset)
plot_field_heatmap(source, title="Dataset source field before conversion")
<xarray.Dataset> Size: 9kB
Dimensions: (batch: 2, time: 17, x: 32, var: 1)
Coordinates:
* time (time) float64 136B 0.0 0.0375 0.075 0.1125 ... 0.525 0.5625 0.6
* x (x) float64 256B 0.0 0.1963 0.3927 0.589 ... 5.498 5.694 5.89 6.087
Dimensions without coordinates: batch, var
Data variables:
u (batch, time, x, var) float64 9kB 0.2347 0.2442 ... 2.525 2.385
Attributes:
source: tutorial_generated_heat
note: attrs are hints, not canonical metadata
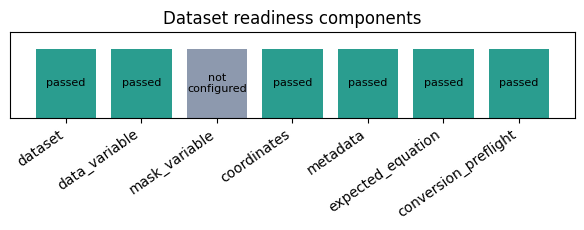
2. Readiness first: a dashboard before conversion#
The readiness report is like an inspection station: data variable, coordinates, metadata, equation tag, and conversion preflight each get their own status.
[3]:
dataset_ready = summarize_xarray_dataset_readiness(
dataset,
metadata=metadata,
expected_equation="heat_1d",
)
print(pretty_json({
"readiness_label": dataset_ready["readiness_label"],
"selected_data_var": dataset_ready["selected_data_var"],
"candidate_variables": dataset_ready["candidate_variables"],
"metadata_suggestions": dataset_ready["metadata_suggestions"],
}, max_chars=4500))
plot_component_statuses(dataset_ready, title="Dataset readiness components")
{
"candidate_variables": [
{
"compatible": true,
"dims": [
"batch",
"time",
"x",
"var"
],
"dtype": "float64",
"failures": [],
"finite": true,
"mask_candidate": false,
"name": "u",
"numeric": true,
"shape": [
2,
17,
32,
1
]
}
],
"metadata_suggestions": {
"boundary_conditions": {
"x": "periodic"
},
"compatible_data_vars": [
"u"
],
"coordinate_system": "cartesian",
"dataset_attr_keys": [
"note",
"source"
],
"grid_regularity": "uniform",
"grid_type": "rectilinear",
"parameter_tags": {
"domain_length": 6.283185307179586
},
"selected_data_var": "u"
},
"readiness_label": "ready",
"selected_data_var": "u"
}
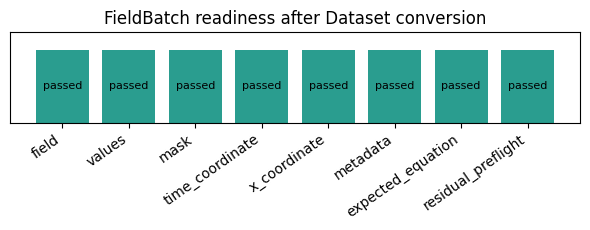
3. Convert exactly one scalar variable into a FieldBatch#
The conversion records a from_xarray_dataset preprocess step, then the existing from_xarray step. That provenance trail matters when your external data flow gets longer.
[4]:
imported = from_xarray_dataset(
dataset,
metadata=metadata,
preprocess_log=[{"operation": "tutorial_dataset_build"}],
)
field_ready = summarize_field_batch_readiness(
imported,
residual_evaluator=HeatResidualEvaluator(),
expected_equation="heat_1d",
)
direct = from_xarray(dataset["u"], metadata=metadata)
print(pretty_json({
"field_snapshot": field_snapshot(imported),
"field_readiness_label": field_ready["readiness_label"],
"preprocess_operations": [entry["operation"] for entry in imported.preprocess_log],
"matches_direct_dataarray_path": bool(np.allclose(imported.values, direct.values)),
}, max_chars=3500))
plot_component_statuses(field_ready, title="FieldBatch readiness after Dataset conversion")
{
"field_readiness_label": "ready",
"field_snapshot": {
"dims": [
"batch",
"time",
"x",
"var"
],
"mask_present": false,
"metadata_parameter_tags": {
"equation": "heat_1d",
"nu": 0.1
},
"preprocess_steps": 3,
"shape": [
2,
17,
32,
1
],
"time_points": 17,
"var_names": [
"u"
],
"x_points": 32
},
"matches_direct_dataarray_path": true,
"preprocess_operations": [
"tutorial_dataset_build",
"from_xarray_dataset",
"from_xarray"
]
}
4. Ambiguity is a feature, not a nuisance#
If a Dataset contains several compatible variables, PDELie refuses to guess. Choose data_var explicitly so the scientific target is visible in code review.
[5]:
ambiguous = dataset.assign(v=dataset["u"] * 0.5)
ambiguous_report = summarize_xarray_dataset_readiness(
ambiguous,
metadata=metadata,
expected_equation="heat_1d",
)
explicit_report = summarize_xarray_dataset_readiness(
ambiguous,
data_var="u",
metadata=metadata,
expected_equation="heat_1d",
)
plot_label_strip(
{
"ambiguous auto-select": ambiguous_report["readiness_label"],
"explicit data_var": explicit_report["readiness_label"],
},
title="Dataset selection policy",
)
print(pretty_json({
"ambiguous_failures": ambiguous_report["component_statuses"]["data_variable"],
"compatible_variables": [item["name"] for item in ambiguous_report["candidate_variables"] if item["compatible"]],
"explicit_selected_data_var": explicit_report["selected_data_var"],
}, max_chars=3500))
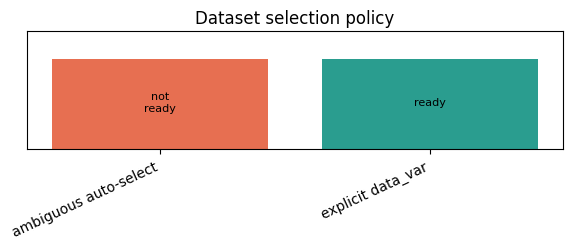
{
"ambiguous_failures": {
"details": {
"failures": [
"ambiguous_data_var"
]
},
"reason": "dataset_data_var_not_ready",
"status": "failed"
},
"compatible_variables": [
"u",
"v"
],
"explicit_selected_data_var": "u"
}
Recap#
V0.29 gives you a narrow Dataset doorway: report first, select one scalar variable, supply explicit metadata, convert to canonical FieldBatch, then reuse the existing residual/readiness/confidence stack.
Common pitfalls#
Treating Dataset attrs as canonical metadata.
Expecting PDELie to pick between several compatible variables.
Passing endpoint-duplicated or nonuniform coordinates into spectral tools.
Reading files directly with PDELie; file loaders remain deferred.
Extension ideas#
Add a valid boolean mask variable and inspect how mask diagnostics change.
Compare Dataset readiness with and without
expected_equation.Use this notebook as the front door for your own xarray preprocessing script.
What to read/run next#
Run 08_downstream_task_template.ipynb to plug the imported FieldBatch into downstream contracts, or 00_pde_timeseries_to_generators.ipynb for the core generator-confidence flow.