Note
This page renders committed notebook outputs. The Read the Docs build does not execute notebook code.
Raw vs translation-canonical discovery inputs#
Current surface: V0.29.
Purpose#
Show how symmetry-aware preprocessing can feed downstream sparse-discovery tooling while keeping the policy boundaries explicit.
What you will learn#
How raw canonical trajectories differ from translation-canonical discovery inputs.
How PySINDy bridge arrays are backend-native, not canonical PDELie objects.
How coverage diagnostics and orbit batches help audit finite translations before downstream use.
Why orbit-expanded data still does not define train/heldout or leakage policy.
Required extras#
.[downstream] or .[test] for PySINDy-related downstream cells; core APIs still run without treating PySINDy outputs as contracts.
Expected runtime#
About 1 minute for the deterministic tutorial cells.
Out of scope#
Not a full discovery benchmark, no manuscript policy, no success threshold policy, no broad discovery-backend framework.
These notebooks are tutorials, not API contracts. Example outputs are runtime summaries, not canonical paper artifacts.
[1]:
import sys
from pathlib import Path
ROOT = Path.cwd()
if not (ROOT / "pyproject.toml").exists():
ROOT = ROOT.parent
if str(ROOT) not in sys.path:
sys.path.insert(0, str(ROOT))
import numpy as np
from notebooks._tutorial_utils import plot_coverage_counts, plot_field_heatmap, pretty_json
from pdelie.data import generate_heat_1d_field_batch
from pdelie.discovery import build_translation_canonical_discovery_inputs, to_pysindy_trajectories
from pdelie.invariants import build_uniform_translation_orbit_batch, compute_periodic_window_coverage
from pdelie.residuals import HeatResidualEvaluator
from pdelie.symmetry import fit_translation_generator
CONFIG = {
"fit_epsilon": 1e-4,
"coverage_shifts": [0.0, np.pi / 2.0, np.pi, 3.0 * np.pi / 2.0],
"coverage_windows": [{"start": 0.0, "width": np.pi / 2.0}],
}
CONFIG
[1]:
{'fit_epsilon': 0.0001,
'coverage_shifts': [0.0,
1.5707963267948966,
3.141592653589793,
4.71238898038469],
'coverage_windows': [{'start': 0.0, 'width': 1.5707963267948966}]}
1. Start from raw trajectories#
The raw batch is already canonical, but individual initial conditions can be translated relative to each other.
[2]:
field = generate_heat_1d_field_batch(batch_size=4, num_times=33, num_points=64, seed=601)
evaluator = HeatResidualEvaluator()
generator = fit_translation_generator(field, evaluator, epsilon=CONFIG["fit_epsilon"])
plot_field_heatmap(field, batch_index=0, title="Raw heat sample 0")
plot_field_heatmap(field, batch_index=1, title="Raw heat sample 1")
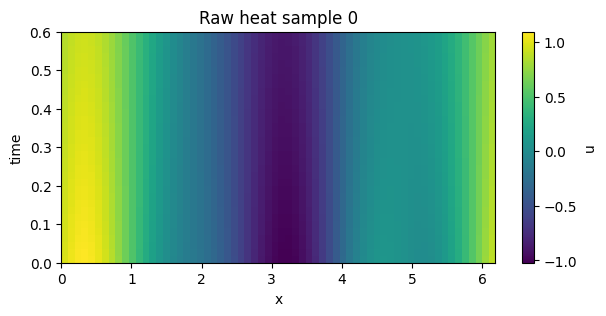
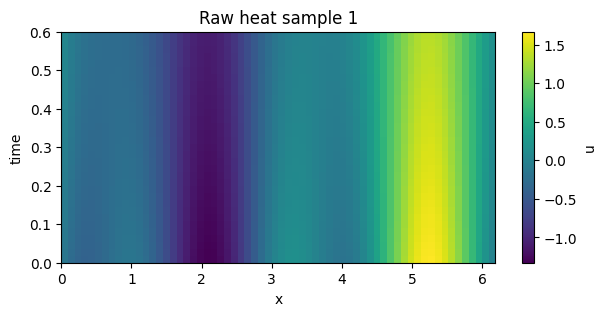
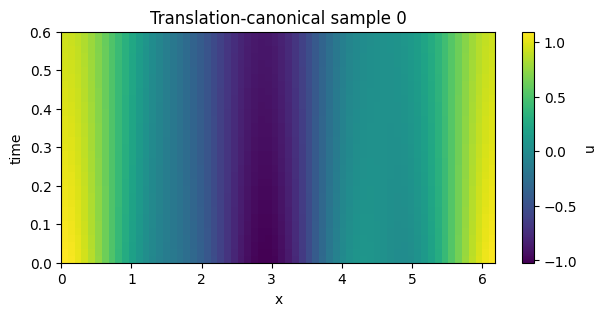
2. Translation-canonical discovery inputs are heuristic, not a proof#
build_translation_canonical_discovery_inputs(...) aligns batch samples and returns backend bridge data. The transformed field is useful for downstream experiments, but the policy is a heuristic peak alignment.
[3]:
canonical = build_translation_canonical_discovery_inputs(field, generator_family=generator)
transformed = canonical["transformed_field"]
trajectories, time_values, feature_names = to_pysindy_trajectories(transformed)
print("alignment shifts:", canonical["alignment_shifts"])
print("trajectory count:", len(trajectories))
print("feature count:", len(feature_names))
plot_field_heatmap(transformed, batch_index=0, title="Translation-canonical sample 0")
alignment shifts: [-0.2945243112740431, -5.301437602932776, -5.792311455056181, -2.454369260617026]
trajectory count: 4
feature count: 64
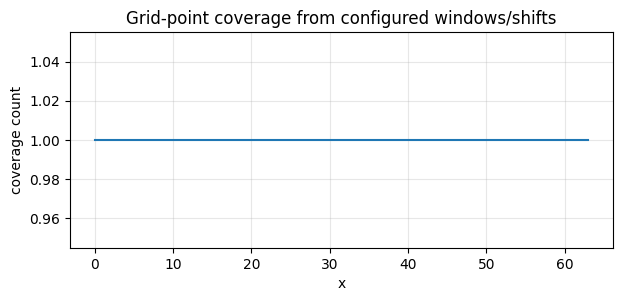
3. Coverage tells you which grid points your finite shifts touch#
Coverage here is grid-point coverage, not continuous interval measure. It is useful for reasoning about observation support before a downstream fit.
[4]:
x = field.coords["x"]
coverage = compute_periodic_window_coverage(
x=x,
windows=CONFIG["coverage_windows"],
shifts=CONFIG["coverage_shifts"],
)
print(pretty_json({k: coverage[k] for k in ("coverage_fraction", "covered_grid_point_count", "max_uncovered_run_points")}))
plot_coverage_counts(coverage, title="Grid-point coverage from configured windows/shifts")
{
"coverage_fraction": 1.0,
"covered_grid_point_count": 64,
"max_uncovered_run_points": 0
}
4. Materialized orbit batches are data utilities, not split policy#
build_uniform_translation_orbit_batch(...) constructs orbit-expanded data. It preserves source and shift provenance, but it does not decide train/heldout policy or protect you from leakage.
[5]:
orbit = build_uniform_translation_orbit_batch(
field,
shifts=CONFIG["coverage_shifts"],
source_field_id="heat_seed_601",
)
print("source shape:", field.values.shape)
print("orbit shape:", orbit.field.values.shape)
print(pretty_json({
"summary_type": orbit.report["summary_type"],
"ordering": orbit.report["ordering"],
"source_batch_indices_head": orbit.report["source_batch_indices"][:8],
"shift_indices_head": orbit.report["shift_indices"][:8],
"warning": "you still own train/heldout split policy",
}))
source shape: (4, 33, 64, 1)
orbit shape: (16, 33, 64, 1)
{
"ordering": "shift_major",
"shift_indices_head": [
0,
0,
0,
0,
1,
1,
1,
1
],
"source_batch_indices_head": [
0,
1,
2,
3,
0,
1,
2,
3
],
"summary_type": "uniform_translation_orbit_batch",
"warning": "you still own train/heldout split policy"
}
Limitations#
This notebook is paper-agnostic by design. PySINDy output names are backend-native labels, not canonical PDELie equation terms. Any downstream success thresholds, train/heldout split choices, or leakage controls belong in your experiment layer.
Recap#
Translation-canonical inputs, coverage reports, and materialized orbit batches are complementary tools for downstream discovery workflows.
Limitations and common pitfalls#
This is not a full sparse-discovery benchmark.
Backend-native PySINDy labels are not canonical PDELie equation terms.
Orbit-expanded data does not decide train/heldout policy or leakage safety.
Discovery thresholds are task policy, not PDELie policy.
Extension ideas#
Replace the Heat fixture with your own canonical
FieldBatch.Compare raw, canonicalized, and orbit-expanded inputs under the same downstream backend.
Add a held-out split before materializing orbits when leakage matters.
What to read/run next#
Run 02_robustness_sweeps.ipynb to stress diagnostic metrics before trusting downstream outputs.